
What is MongoDB? A quick guide for developers
NoSQL data retailers revolutionized application growth by allowing for extra flexibility in how data is managed. One of the preeminent NoSQL answers is MongoDB, a document-oriented data retailer. We’ll take a look at what MongoDB is and how it can cope with your application requirements in this short article.
MongoDB: A document data retailer
Relational databases retailer data in strictly regulated tables and columns. MongoDB is a document retailer, which retailers data in collections and paperwork. The major big difference here is that collections and paperwork are unstructured, from time to time referred to as schema-fewer. This usually means the framework of a MongoDB occasion (the collections and paperwork) is not predefined and flexes to accommodate whatsoever data is put in it.
A document is a important-worth established, which behaves pretty equivalent to an item in code like JavaScript: Its framework changes according to the data put in it. This helps make coding against a data retailer like MongoDB less difficult and extra agile than coding against a relational data retailer. Simply just put, the interaction in between application code and a document data retailer feels extra organic.
Determine one offers a visual glimpse at the framework of MongoDB databases, collections, and paperwork.
Determine one. MongoDB document retailer
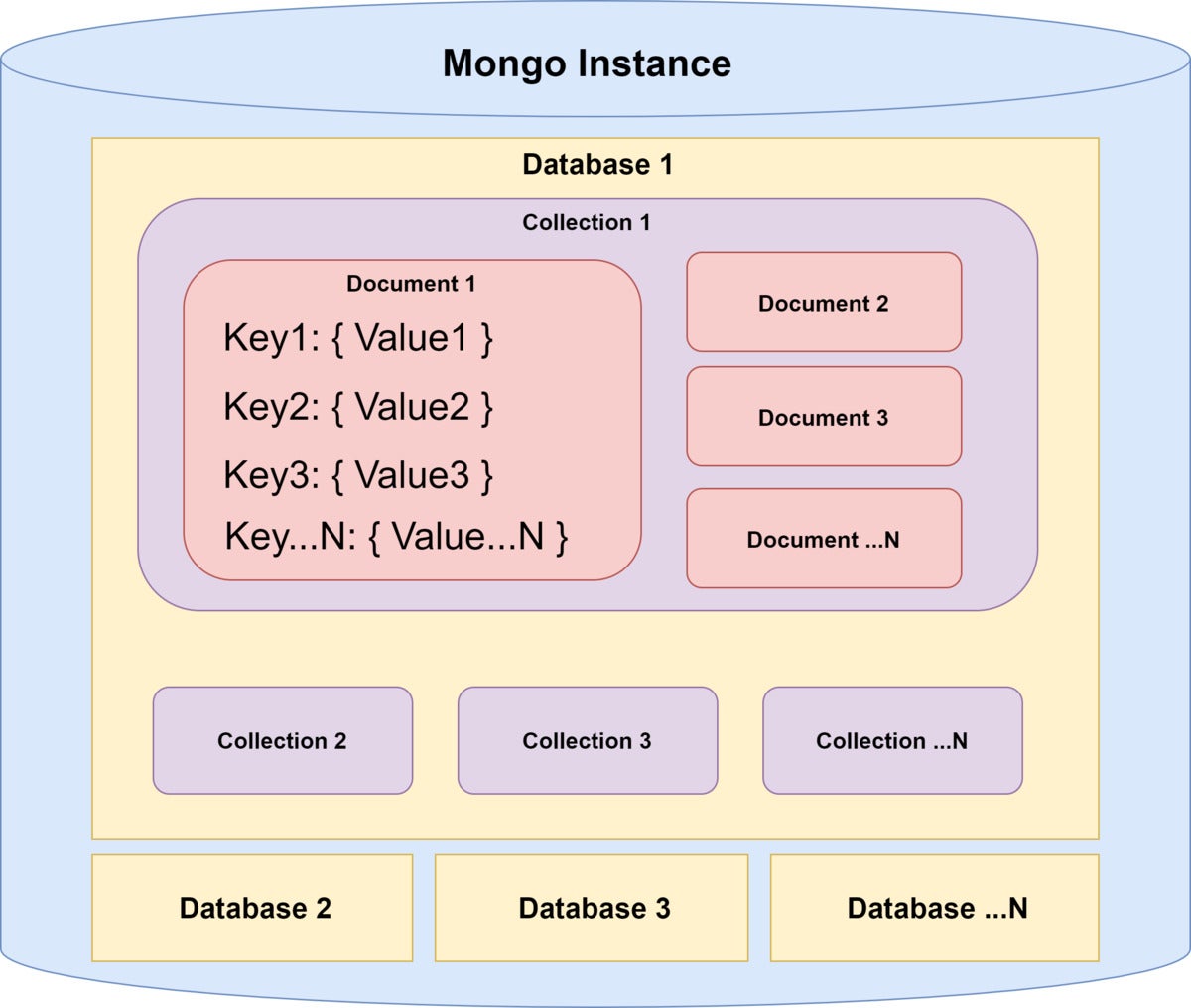 IDG
IDGThe flexibility inherit in this style of data modeling usually means that data can be handled on a extra as-use-calls for foundation, enabling functionality rewards as described here.
To get a concrete knowing of this big difference, examine the adhering to two techniques to attain the exact undertaking (making a record and then incorporating a industry from an application), 1st in a relational databases and then in MongoDB.
The ways in a relational databases:
# build a databases:
Make Databases menagerie# build a desk in the databases:
USE menagerie Make Table pet (title VARCHAR(20))# hook up to the databases in application and problem insert:
INSERT INTO pet (title) VALUES ('Friar Tuck')# increase a column:
Alter Table pet Incorporate style VARCHAR(20))# update current record:
UPDATE pet Established style = 'cat' Where title = 'Friar Tuck'
Now for the exact system with MongoDB:
# hook up to the databases in application and problem insert:
use menagerie db.pet.insertOne(title:"friar tuck")# problem update:
db.pet.updateOne( title:'friar tuck' , $established: style: 'cat' )
From the preceding you can get a feeling of how substantially smoother the growth experience can be with MongoDB.
This flexibility of program puts the load upon the developer to stay clear of schema bloat. Keeping a grip on the document framework for big-scale apps is critical.
The ID industry in MongoDB
In a relational databases, you have the strategy of a major important, and this is usually a artificial ID column (that is to say, a created worth not related to the business data). In MongoDB, each and every document has an _id industry of equivalent objective. If you as the developer do not present an ID when making the document, just one will be vehicle-created (as a UUID) by the MongoDB motor.
Like a major important, the _id industry is instantly indexed and need to be exceptional.
Indexing in MongoDB
Indexing in MongoDB behaves likewise to indexing in a relational databases: It makes extra data about a document’s industry to velocity up lookups that rely on that industry. MongoDB works by using B-Tree indexes.
An index can be made with syntax like so:
db.pet.createIndex( title: one )
The integer in the parameter signifies irrespective of whether the index is ascending (one) or descending (-one).
Nesting paperwork in MongoDB
A highly effective facet of the document-oriented framework of MongoDB is that paperwork can be nested. For example, as an alternative of making yet another desk to retailer the address data for the pet document, you could build a nested document, with a framework like Listing one.
Listing one. Nested document example
"_id": "5cf0029caff5056591b0ce7d",
"title": "Friar Tuck",
"address":
"avenue": "Feline Lane",
"town": "Large Sur",
"state": "CA",
"zip": "93920"
,
"style": "cat"
Denormalization in MongoDB
Denormalization is not a need, but extra of a tendency when working with document-oriented databases. This is for the reason that of the enhanced capacity to offer with advanced nested data, as opposed to the SQL tendency to preserve data normalized (i.e., not duplicated) into specific, one-worth columns.
MongoDB query language
The query language in MongoDB is JSON-oriented, just like the document framework. This helps make for a pretty highly effective and expressive syntax that can cope with even advanced nested paperwork.
For example, you could query our theoretical databases for all cats by issuing db.pet.uncover( "style" : "cat" ) or all cats in California with db.pet.uncover( "style" : "cat", "address.state": "CA" ). Recognize that the query language traverses the nested address document.
MongoDB update syntax
MongoDB’s alter syntax also works by using a JSON-like structure, where the $established keyword signifies what industry will adjust, to what worth. The established item supports nested paperwork through the dot notation, as in Listing two, where you adjust the zip code for the cat named “Friar Tuck.
Listing two. Updating a nested document
db.individuals.update(
"style": "cat",
"title": "Friar Tuck"
,
$established:
"address.zip": "86004"
)
You can see from Listing two that the update syntax is each and every little bit as highly effective — in fact extra highly effective — than the SQL equivalent.
MongoDB cloud and deployment solutions
MongoDB is intended for scalability and distributed deployments. It is entirely able of managing world wide web-scale workloads.
MongoDB the company features a multicloud databases clustering solution in MongoDB Atlas. MongoDB Atlas functions like a managed databases that can span different cloud platforms, and includes organization options like monitoring and fault tolerance.
You get an sign of MongoDB’s importance in that AWS’s Amazon DocumentDB giving includes MongoDB compatibility as a chief selling place. Microsoft’s Azure Cosmos DB follows a equivalent pattern with MongoDB API guidance.
Significant availab
ility in MongoDB
MongoDB supports replica sets for high availability. The core thought is that data is published the moment to a major occasion, then duplicated to secondary retailers for reads. Study extra about replication in MongoDB here.
The bottom line is that MongoDB is a foremost NoSQL solution that provides on the assure of flexible-schema data retailers. Superior drivers are out there for rather substantially each and every programming language, and you can draw on a multitude of deployment solutions as effectively.
For extra particulars on working with MongoDB, see this short article on working with MongoDB with Node.js. You can learn about other NoSQL solutions and how to select among them here.
Copyright © 2021 IDG Communications, Inc.







