
Rethinking data architectures for a cloud world
Facts analytics solutions are continuing to arise at a speedy and furious price. Facts teams are at the centre of the storm for the reason that they have to stability all the requires for obtain, knowledge integrity, protection, and good governance, which entails compliance with procedures and rules. The firms they provide want facts as rapidly as attainable and have minor endurance for that precarious balancing act. The knowledge teams have to go speedy and intelligent.
They also have to be fortune tellers for the reason that they want to make not just the devices for currently, but also the platforms for tomorrow. The very first key question the knowledge team have to contemplate is: open or shut knowledge architectures.
Open up vs. shut knowledge architecture
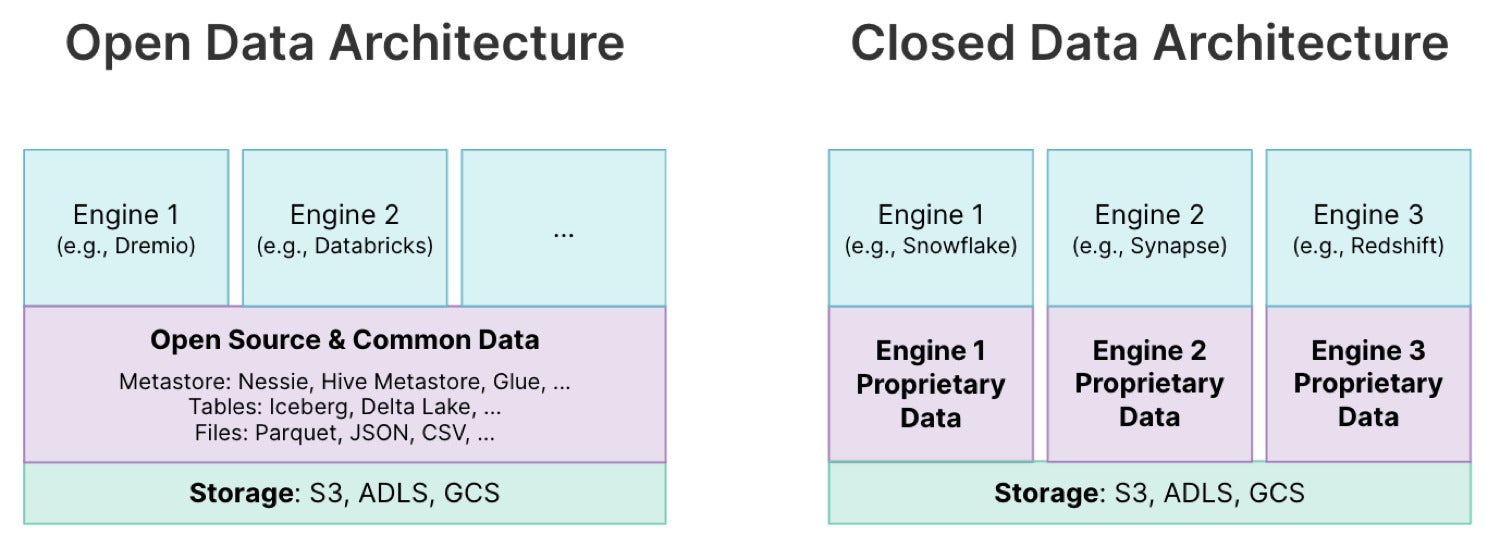
Let us commence with the phrase “data architectures.” If I were to present you an architecture diagram from any business over the very last 50 decades, odds are that their labels for knowledge would in reality be labels symbolizing databases—not the knowledge itself, but the engines that act upon the knowledge. Names below are acquainted, both of those aged and new: Oracle, DB2, SQL Server, Teradata, Exadata, Snowflake, and so on. These are all databases into which you load your datasets for either operational or analytical purposes, and they are the foundations of the “data architecture.”
By definition, these databases are what we would get in touch with “closed knowledge architectures.” Which is not a benefit statement it is a descriptive a single. It usually means that the knowledge itself is shut off from other apps and have to be accessed by way of the databases motor. This is true even for relocating knowledge around with ETL positions for the reason that at some position, to do the export or the import, you want to go by way of the databases, no matter if which is the exceptional way to accomplish what you want to do or not. The knowledge is “closed” off from the relaxation of the architecture in this important feeling.
In distinction, an “open knowledge architecture” is a single that outlets the knowledge in its very own impartial tier within just the architecture, which makes it possible for distinct greatest-of-breed engines to be utilized for an organization’s wide range of analytic wants. Which is important for the reason that there is hardly ever been a silver bullet when it will come to analytic processing wants, and there most likely hardly ever will be. An open architecture puts you in an perfect posture to be in a position to use no matter what greatest-of-breed products and services exist currently or in the potential.
To summarize: A shut knowledge architecture delivers the knowledge to a databases motor, and an open knowledge architecture delivers the databases motor to the knowledge.
 Dremio
DremioAn uncomplicated way to take a look at if you are working with an open architecture is to contemplate how challenging it would be in the potential to undertake a new motor. Will you be in a position to run the new motor aspect by aspect with an existing a single (on the similar knowledge), or will a wholesale (and most likely impractical) migration be needed?
Note at this position, we have touched on a critical element of “open” that has almost nothing to do with open resource. Action a single is deciding that you want your knowledge open and offered to any products and services that wish to get benefit of it, and that delivers us to open in a cloud earth.
Open up, products and services-oriented knowledge architecture
When apps moved from consumer-server to web, the fundamental architecture adjusted. We went from monolithic apps that ran in a single approach, to products and services-oriented apps that were damaged into smaller, additional specialized program products and services. Inevitably, these became recognised as “microservices” and they continue being the dominant design for web and cell apps. The microservices method held numerous advantages that were understood owing to the nature of cloud infrastructure. In a scale-out system with on-demand from customers useful resource models and quite a few teams functioning on pieces of operation, the “application” became almost nothing additional than a facade for dozens or hundreds of microservices.
Everybody agrees that this method has numerous advantages for making modular and scalable apps. For some cause, we’re envisioned to imagine that this paradigm is not practically as productive for knowledge. At Dremio, we imagine which is inaccurate. We imagine the logic of searching at our knowledge in the similar open, products and services-oriented manner as our apps is intuitively evident and desirable. On a functional and strategic stage, an open, products and services-oriented knowledge architecture just tends to make feeling.
Which is why, for us, the concern of open resource program is secondary. The principal “open” that matters most is the very first stage of deciding an open knowledge architecture is additional desirable than a shut a single. The moment that occurs, a watershed of goodness is unleashed. Open up file and desk formats (Apache Parquet, Apache Iceberg, and so on.) are critical as they make it possible for for field-vast innovation. That innovation will get sent in the type of products and services that act upon the impartial knowledge tier. Messy, expensive, fragile, and compliance-undermining copying of knowledge is drastically minimized or even removed. The knowledge team will get to pick from greatest-of-breed products and services to act upon that knowledge, slotting them into the architecture the similar way we have been accomplishing with application products and services for additional than a ten years. It is time for knowledge architectures to catch up.
There is a single genuine declare levied by these disputing the benefit of open knowledge architectures: They’re way too complex. Complication will come with any major technological shift. Midrange computers were at first additional complex to manage than set up mainframes. Then Intel-centered servers were at first additional complex to manage than set up midrange devices. Controlling PCs was at first additional complex than managing set up dumb terminals. You see the position. Each and every time a engineering shift occurs, it goes by way of the standard adoption curve into the mainstream. The early days are always additional complex from a management point of view, but with time, new resources and methods lessen that complexity, ensuing in the positive aspects significantly outweighing the initial complexity cost. Which is why we have innovation.
Dremio was made to make an open, products and services-oriented knowledge architecture a lot, a lot simpler and additional strong. With Dremio, running SQL from a lakehouse is uncomplicated for the reason that of the way we place all the pieces collectively. And we have made field-altering open resource assignments together the way, these types of as Nessie, Apache Arrow, and Arrow Flight. These are open resource assignments for the reason that open resource engineering encourages adoption and interoperability, which are critical for provider integration levels in an organization’s knowledge architecture. Everybody wins. Clients gain for the reason that they get a collective field functioning on and innovating key pieces of engineering to superior provide them. Open up resource enthusiasts gain for the reason that they get obtain to the code to superior fully grasp it, and even increase it. And we gain for the reason that we use these improvements to make SQL on lakehouses speedy and uncomplicated.
To place a great position on this discussion, the truth is that no subject how “open” a vendor statements to be, no subject how a lot they discuss about supporting open formats and open criteria, even if that vendor was open resource at its core, if the knowledge architecture is shut, it is shut. Period.
Facts as a very first-class citizen
At Dremio we’re advocating for a earth the place the knowledge itself gets to be a very first-class citizen in the architecture. We’re making that simpler and simpler to recognize for organizations that want the positive aspects of an open architecture, these types of as: (one) flexibility to use greatest-of-breed engines greatest suited for distinct positions (two) keeping away from getting locked into heading by way of a proprietary motor in order to obtain their knowledge (3) location on their own up to get benefit of tomorrow’s improvements and (four) eradicating the complexity that infinite copying and relocating of knowledge into and out of knowledge warehouses has made.
We’re not only dedicated to open criteria and open resource, important as they may possibly be—we’re very first and foremost dedicated to open knowledge architectures. We imagine that as they turn out to be simpler and simpler to employ and use, the advantages are overpowering when as opposed to a shut knowledge architecture. We’re also dedicated to equipping and educating people on this journey with initiatives like our Subsurface field conference, which captivated over 10,000 attendees in our very first-ever events very last yr. The momentum is making and the spot is a potential with open knowledge architectures at its core.
Tomer Shiran is co-founder and chief product or service officer at Dremio.
—
New Tech Discussion board provides a venue to check out and discuss rising business engineering in unprecedented depth and breadth. The selection is subjective, centered on our select of the systems we imagine to be important and of finest desire to InfoWorld audience. InfoWorld does not accept marketing collateral for publication and reserves the suitable to edit all contributed written content. Ship all inquiries to [email protected].
Copyright © 2021 IDG Communications, Inc.






