There is a lot interest in cloud information lakes, an evolving technological innovation that can enable companies to greater handle and analyze information.
At the Subsurface digital conference on July thirty, sponsored by information lake motor seller Dremio, companies such as Netflix and Exelon Utilities, outlined the systems and approaches they are utilizing to get the most out of the information lake architecture.
The primary assure of the modern cloud information lake is that it can individual the compute from storage, as effectively as enable to avert the hazard of lock-in from any a person vendor’s monolithic information warehouse stack.
In the opening keynote, Dremio CEO Billy Bosworth said that, even though there is a great deal of buzz and interest in information lakes, the reason of the conference was to glimpse beneath the surface area — therefore the conference’s identify.
“What is actually actually crucial in this model is that the information itself gets unlocked and is no cost to be accessed by several various systems, which indicates you can opt for finest of breed,” Bosworth said. “No for a longer time are you compelled into a person option that may perhaps do a person issue actually effectively, but the rest is kind of average or subpar.”
Why Netflix produced Apache Iceberg to enable a new information lake model
In a keynote, Daniel Months, engineering supervisor for Massive Data Compute at Netflix, talked about how the streaming media seller has rethought its approach to information in new decades.
“Netflix is actually a really information-pushed enterprise,” Months said. “We use information to impact conclusions around the business, around the solution content — ever more, studio and productions — as effectively as several interior initiatives, such as A/B testing experimentation, as effectively as the genuine infrastructure that supports the platform.”
What is actually actually crucial in this model is that the information itself gets unlocked and is no cost to be accessed by several various systems, which indicates you can opt for finest of breed. Billy BosworthCEO, Dremio
Netflix has a lot of its information in Amazon Simple Storage Assistance (S3) and had taken various techniques more than the decades to enable information analytics and management on prime. In 2018, Netflix started off an interior exertion, recognised as Iceberg, to attempt to construct a new overlay to generate structure out of the S3 information. The streaming media big contributed Iceberg to the open up resource Apache Program Basis in 2019, where it is under lively improvement.
“Iceberg is actually an open up desk format for huge analytic information sets,” Months said. “It is an open up neighborhood conventional with a specification to guarantee compatibility across languages and implementations.”
Iceberg is continue to in its early days, but beyond Netflix, it is currently getting adoption at other effectively-recognised brand names such as Apple and Expedia.
Not all information lakes are in the cloud, however
While a lot of the emphasis for information lakes is on the cloud, among the the technological user classes at the Subsurface conference was a person about an on-premises approach.
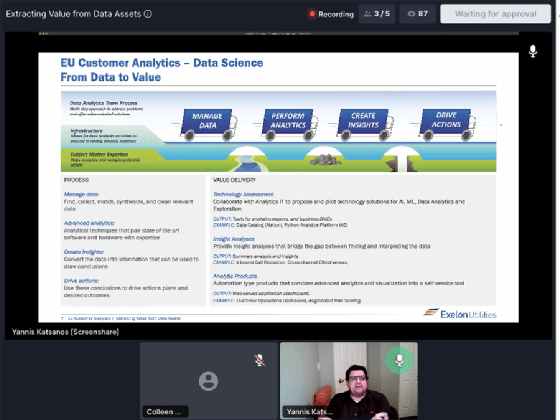
Yannis Katsanos, head of client information science at Exelon Utilities, detailed in a session the on-premises information lake management and information analytics approach his business normally takes.
Yannis Katsanos, head of client information science at Exelon Utilities, discussed how his business gets worth out of its large information sets.
Exelon Utilities is a person of the biggest electricity era conglomerates in the earth, with 32,000 megawatts of total electricity-producing capability. The enterprise collects information from good meters, as effectively as its electricity crops, to enable tell business intelligence, organizing and standard functions. The utility attracts on hundreds of various information resources for Exelon and its functions, Katsanos said.
“Every working day I’m stunned to locate out there is a new information resource,” he said.
To enable its information analytics method, Exelon has a information integration layer that will involve ingesting all the information resources into an Oracle Massive Data Appliance, utilizing a number of systems such as Apache Kafka to stream the information. Exelon is also utilizing Dremio’s Data Lake Motor technological innovation to enable structured queries on prime of all the collected information.
While Dremio is normally affiliated with cloud information lake deployments, Katsanos pointed out Dremio also has the adaptability to be put in on premises as effectively as in the cloud. Presently, Exelon is not utilizing the cloud for its information analytics workloads, nevertheless, Katsanos pointed out, it is really the course for the future.
The evolution of information engineering to the information lake
The use of information lakes — on premises and in the cloud — to enable make conclusions is currently being pushed by a quantity of economic and technological elements. In a keynote session, Tomasz Tunguz, managing director at Redpoint Ventures and a board member of Dremio, outlined the essential developments that he sees driving the future of information engineering initiatives.
Among them is a transfer to define information pipelines that enable companies to transfer information in a managed way. A different essential development is the adoption of compute engines and conventional doc formats to enable people to question cloud information devoid of having to transfer it to a particular information warehouse. There is also an expanding increasing landscape of various information solutions aimed at assisting people derive insight from information, he included.
“It is actually early in this decade of information engineering I really feel as if we are six months into a 10-yr-lengthy motion,” Tunguz said. “We will need information engineers to weave together all of these various novel systems into lovely information tapestry.”