
How to count by group in R
Counting by various teams — often named crosstab reviews — can be a valuable way to appear at knowledge ranging from public feeling surveys to clinical tests. For case in point, how did persons vote by gender and age group? How quite a few program developers who use the two R and Python are men vs. women of all ages?
There are a good deal of means to do this variety of counting by types in R. Here, I’d like to share some of my favorites.
For the demos in this posting, I’ll use a subset of the Stack Overflow Developers survey, which surveys developers on dozens of topics ranging from salaries to technologies made use of. I’ll whittle it down with columns for languages made use of, gender, and if they code as a interest. I also added my personal LanguageGroup column for regardless of whether a developer noted working with R, Python, the two, or neither.
If you’d like to stick to along, the very last webpage of this posting has recommendations on how to down load and wrangle the knowledge to get the very same knowledge established I’m working with.
The knowledge has one row for each and every survey response, and the four columns are all figures.
str(mydata) 'data.frame':83379 obs. of 4 variables: $ Gender : chr "Guy" "Guy" "Guy" "Guy" ... $ LanguageWorkedWith: chr "HTML/CSSJavaJavaScriptPython" "C++HTML/CSSPython" "HTML/CSS" "CC++C#PythonSQL" ... $ Hobbyist : chr "Yes" "No" "Yes" "No" ... $ LanguageGroup : chr "Python" "Python" "Neither" "Python" ...
I filtered the uncooked knowledge to make the crosstabs a lot more workable, together with eliminating missing values and getting the two biggest genders only, Guy and Lady.
The janitor offer
So, what’s the gender breakdown inside of each and every language group? For this type of reporting in a knowledge frame, one of my go-to tools is the janitor package’s tabyl() purpose.
The standard tabyl() purpose returns a knowledge frame with counts. The initially column title you incorporate to a tabyl() argument will become the row, and the second one the column.
library(janitor) tabyl(mydata, Gender, LanguageGroup)
Gender Each Neither Python R Guy 3264 43908 29044 969 Lady 374 3705 1940 175
What’s awesome about tabyl() is it’s very simple to produce percents, way too. If you want to see percents for each and every column as a substitute of uncooked totals, incorporate adorn_percentages("col"). You can then pipe individuals effects into a formatting purpose these as adorn_pct_formatting().
tabyl(mydata, Gender, LanguageGroup) %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = one)Gender Each Neither Python R Guy 89.seven% ninety two.2% ninety three.seven% 84.seven% Lady ten.3% seven.8% 6.3% fifteen.3%
To see percents by row, incorporate adorn_percentages("row").
If you want to incorporate a third variable, these as Hobbyist, that is simple way too.
tabyl(mydata, Gender, LanguageGroup, Hobbyist) %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = one)
Nevertheless, it will get a tiny more durable to visually examine effects in a lot more than two ranges this way. This code returns a list with one knowledge frame for each and every third-degree selection:
$No
Gender Each Neither Python R
Guy 79.6% 86.seven% 86.4% 74.6%
Lady 20.4% thirteen.3% thirteen.6% 25.4%
$Yes
Gender Each Neither Python R
Guy ninety one.6% ninety three.nine% 95.% 88.%
Lady 8.4% 6.one% five.% twelve.%
The CGPfunctions offer
The CGPfunctions offer is truly worth a appear for some fast and simple means to visualize crosstab knowledge. Put in it from CRAN with the normal install.offers("CGPfunctions").
The offer has two functions of fascination for examining crosstabs: PlotXTabs() and PlotXTabs2(). This code returns bar graphs of the knowledge (initially graph below):
library(CGPfunctions)
PlotXTabs(mydata)
 Monitor shot by Sharon Machlis, IDG
Monitor shot by Sharon Machlis, IDGResult of PlotXTabs(mydata).
PlotXTabs2(mydata) creates a graph with a different appear, and some statistical summaries (next graph at remaining).
If you don’t want or want individuals summaries, you can take away them with effects.subtitle = Phony, these as PlotXTabs2(mydata, LanguageGroup, Gender, effects.subtitle = Phony).
 Monitor shot by Sharon Machlis, IDG
Monitor shot by Sharon Machlis, IDGResult of PlotXTabs(mydata).
PlotXTabs2() has a couple of dozen argument options, together with title, caption, legends, shade scheme, and one of four plot forms: side, stack, mosaic, or percent. There are also options familiar to ggplot2 customers, these as ggtheme and palette. You can see a lot more aspects in the function’s support file.
The vtree offer
The vtree offer generates graphics for crosstabs as opposed to graphs. Running the major vtree() purpose on one variable, these as
library(vtree)
vtree(mydata, "LanguageGroup")
will get you this standard response:
 Sharon Machlis, IDG
Sharon Machlis, IDGSimple vtree() purpose on one variable.
I’m not eager on the shade defaults here, but you can swap in an RColorBrewer palette. vtree’s palette argument makes use of palette quantities, not names you can see how they are numbered in the vtree offer documentation. I could opt for 3 for Greens and five for Purples, for case in point. Sadly, individuals defaults give you a a lot more rigorous shade for lower count quantities, which doesn’t often make feeling (and doesn’t operate very well for me in this case in point). I can change that default behavior with sortfill = Real to use the a lot more rigorous shade for the increased benefit.
vtree(mydata, "LanguageGroup", palette = 3, sortfill = Real)
 Sharon Machlis, IDG
Sharon Machlis, IDGvtree() soon after switching to a new palette.
If you find the dark shade will make it difficult to examine text, there are some options. A single selection is to use the simple argument, these as vtree(mydata, "LanguageGroup", simple = Real). Another selection is to established a solitary fill color instead of a palette, working with the fillcolor argument, these as vtree(mydata, LanguageGroup", fillcolor = "#99d8c9").
To appear at two variables in a crosstab report, simply just incorporate a next column title and palette or shade if you don’t want the default. You can use the simple selection or specify two palettes or two colours. Underneath I chose unique colours as a substitute of palettes, and I also rotated the graph to examine vertically.
vtree(mydata, c("LanguageGroup", "Gender"),
fillcolor = c( LanguageGroup = "#e7d4e8", Gender = "#99d8c9"),
horiz = Phony)
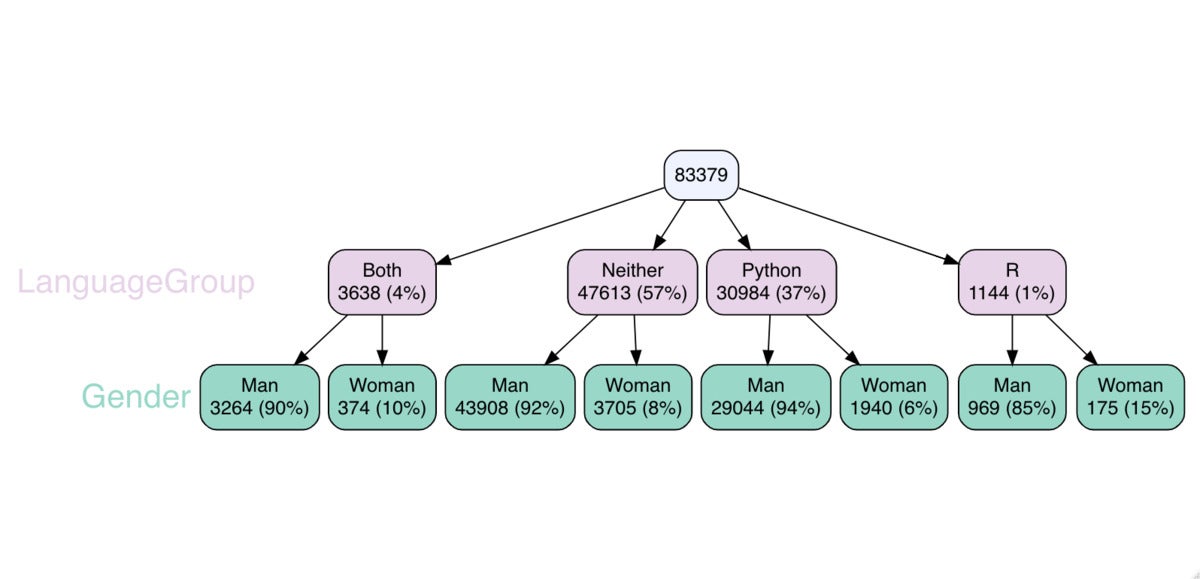 Sharon Machlis, IDG
Sharon Machlis, IDGvtree() for two variables.
You can incorporate a lot more than two types, although it will get a bit more durable to examine and stick to as the tree grows. If you’re only intrigued in some of the branches, you can specify which to show with the maintain argument. Underneath, I established vtree() to demonstrate only persons who use R without having Python or who use the two R and Python.
vtree(mydata, c("Gender", "LanguageGroup", "Hobbyist"),
horiz = Phony, fillcolor = c(LanguageGroup = "#e7d4e8",
Gender = "#99d8c9", Hobbyist = "#9ecae1"),
maintain = list(LanguageGroup = c("R", "Each")), showcount = Phony)
With the tree getting so occupied, I imagine it allows to have both the count or the percent as node labels, not the two. So that very last argument in the code over, showcount = Phony, sets the graph to show only percents and not counts.
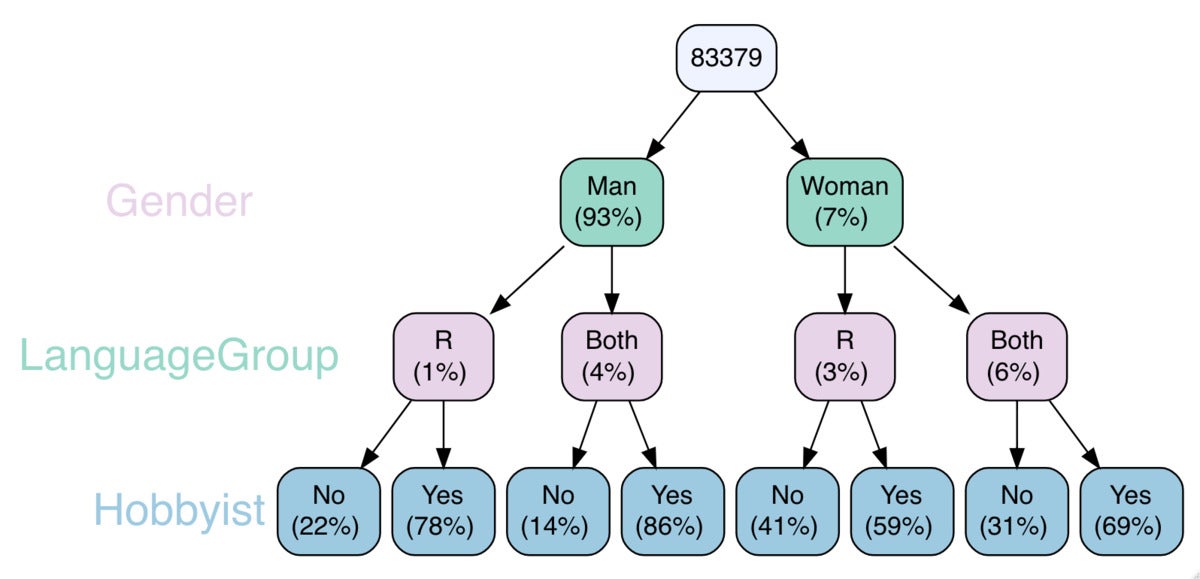 Sharon Machlis, IDG
Sharon Machlis, IDGA few-degree vtree graphic with a subset of nodes, exhibiting percents only.
Extra count by group options
There are other valuable means to group and count in R, together with base R, dplyr, and knowledge.desk. Base R has the xtabs() purpose particularly for this undertaking. Observe the formula syntax below: a tilde and then one variable plus yet another variable.
xtabs(~ LanguageGroup + Gender, knowledge = mydata)
Gender LanguageGroup Guy Lady Each 3264 374 Neither 43908 3705 Python 29044 1940 R 969 175
dplyr’s count() purpose brings together “group by” and “count rows in each and every group” into a solitary purpose.
library(dplyr)
my_summary <- mydata %>%
count(LanguageGroup, Gender, Hobbyist, type = Real)my_summary LanguageGroup Gender Hobbyist n one Neither Guy Yes 34419 2 Python Guy Yes 25093 3 Neither Guy No 9489 4 Python Guy No 3951 five Each Guy Yes 2807 6 Neither Lady Yes 2250 seven Neither Lady No 1455 8 Python Lady Yes 1317 nine R Guy Yes 757 ten Python Lady No 623 11 Each Guy No 457 twelve Each Lady Yes 257 thirteen R Guy No 212 14 Each Lady No 117 fifteen R Lady Yes 103 16 R Lady No 72
In the three strains of code below, I load the knowledge.desk offer, make a knowledge.desk from my knowledge, and then use the special .N knowledge.desk image that stands for quantity of rows in a group.
library(knowledge.desk)
mydt <- setDT(mydata)
mydt[, .N, by = .(LanguageGroup, Gender, Hobbyist)]
Visualizing with ggplot2
As with most knowledge, ggplot2 is a great selection to visualize summarized effects. The initially ggplot graph below plots LanguageGroup on the X axis and the count for each and every on the Y axis. Fill shade signifies regardless of whether another person claims they code as a interest. And, side_wrap claims: Make a individual graph for each and every benefit in the Gender column.
library(ggplot2)
ggplot(my_summary, aes(LanguageGroup, n, fill = Hobbyist)) +
geom_bar(stat = "identity") +
side_wrap(sides = vars(Gender))
 Sharon Machlis, IDG
Sharon Machlis, IDGApplying ggplot2 to examine language use by gender.
Due to the fact there are fairly number of women of all ages in the sample, it’s difficult to examine percentages throughout genders when the two graphs use the very same Y-axis scale. I can change that, while, so each and every graph makes use of a individual scale, by adding the argument scales = “free_y” to the side_wrap() purpose:
ggplot(my_summary, aes(LanguageGroup, n, fill = Hobbyist)) +
geom_bar(stat = "identity") +
side_wrap(sides = vars(Gender), scales = "free_y")
Now it’s less complicated to examine various variables by gender.
For a lot more R recommendations, head to the “Do Extra With R” webpage on InfoWorld or check out the “Do Extra With R” YouTube playlist.
See the subsequent webpage for info on how to down load and wrangle knowledge made use of in this demo.






