
How Grafana Tempo simplifies distributed tracing
Of the three pillars of observability, traces have traditionally lagged guiding logs and metrics in use. We’re hoping to change that with Grafana Tempo, an simple-to-operate, higher-scale, and price tag-productive distributed tracing back again stop.
Tempo makes it possible for end users to scale tracing as far as feasible with fewer operational price tag and complexity than at any time before. Tempo’s only dependency is object storage, and it supports search exclusively via trace ID. As opposed to other tracing back again finishes, Tempo can strike enormous scale with out a complicated-to-deal with Elasticsearch or Cassandra cluster.
We released this open supply undertaking in Oct 2020, and just seven months afterwards, we’re excited to announce that Tempo has attained GA with v1..
In the previous months we have largely been focused on steadiness, horizontally sharding the query route, and overall performance advancements to improve scale. We have also notably extra compression to the back again-stop traces and publish-forward log, which lowers nearby disk I/O and whole storage demanded to cope with your traces.
In this write-up, we’ll wander by means of an overview of distributed tracing, and what Tempo provides to the desk.
Why distributed tracing?
Though metrics and logs can do the job alongside one another to pinpoint a trouble, they each deficiency important components. Metrics are excellent for aggregations but deficiency fantastic-grained details. Logs are excellent at revealing what occurred sequentially in an application, or possibly even across purposes, but they really don’t clearly show how a solitary ask for possibly behaves within of a company. Logs will notify us why a company is possessing issues, but possibly not why a specified ask for is possessing issues.
This is the place tracing will come in. Dispersed tracing is a way to monitor and log a solitary ask for as it crosses by means of all of the providers in your infrastructure.
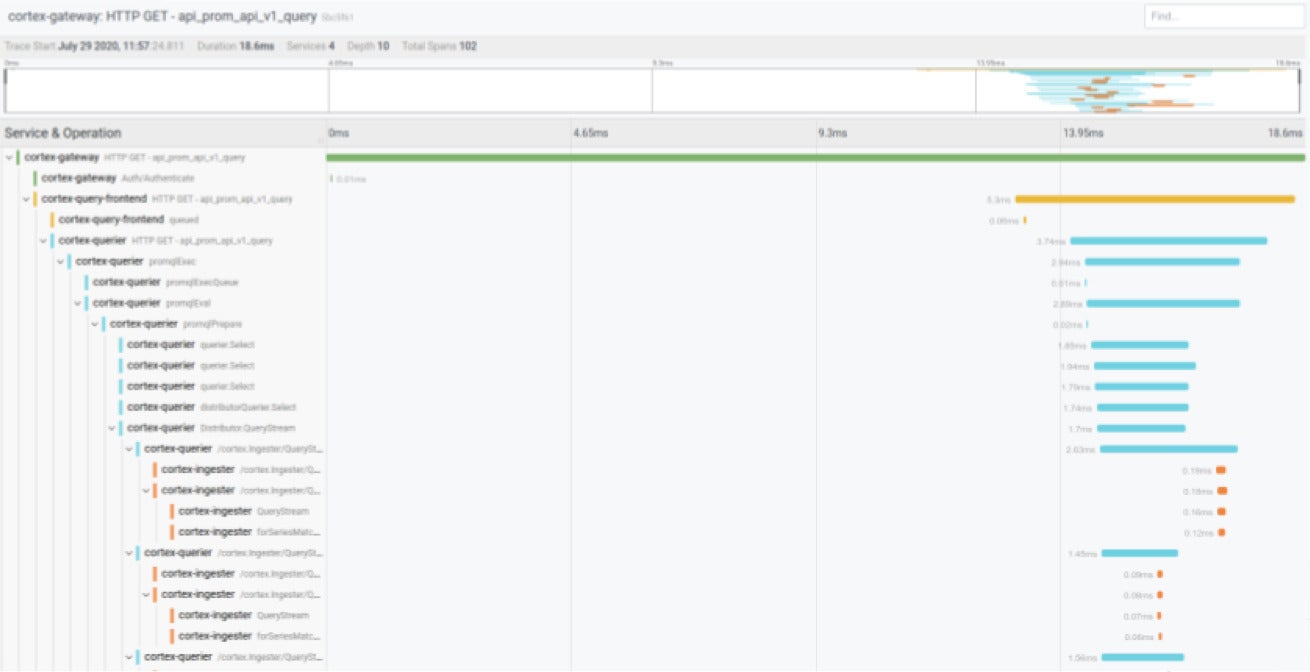 Grafana Labs
Grafana LabsThe display image previously mentioned demonstrates a Prometheus query that is handed down by means of four distinct providers in about 18 milliseconds. There is a lot of depth about how the ask for is handled. If this ask for took 10 seconds, then the trace could notify us precisely the place it expended these 10 seconds—and potentially why it expended time in certain areas—to enable us understand what’s likely on in an infrastructure or how to correct a trouble.
In tracing, spans are representations of models of do the job in a specified application, and they are represented by all of the horizontal bars in the query previously mentioned. If we designed a query to a back again stop, to a database, or to a caching server, we could wrap these in spans to get details about how long each and every of these pieces took.
Spans are linked to each and every other in a handful of distinct approaches, but largely by a dad or mum-boy or girl connection. So in the query previously mentioned, there are two linked spans in which promqlEval is the dad or mum and promqlPrepare is a boy or girl. This connection is how our tracing back again stop is in a position to choose all these spans, rebuild them into a solitary trace, and return that trace when we talk to for it.
Why Grafana Tempo?
At Grafana Labs, we were discouraged with our down-sampled distributed tracing method. Obtaining a sample trace was commonly not complicated, but our engineers normally required to obtain a particular trace.
We required our tracing method to be in a position to always reply inquiries like, “Why was this customer’s query sluggish?” Or “An intermittent bug showed up once more. Can I see the exact trace?”
We resolved we required 100% sampling, but we did not want to deal with the Elasticsearch or Cassandra cluster demanded to pull it off.
Then we recognized that our tracing back again stop did not require to index our traces. We could explore traces by means of logs and exemplars. Why pay back to index your traces and your logs and your metrics? All we necessary was a way to keep traces by ID. And that is why we established Tempo.
 Grafana Labs
Grafana LabsTempo is utilized to ingest and keep the whole browse route of Grafana Labs’ manufacturing, staging, and enhancement environments. At the moment we are ingesting two.two million spans for every next and storing 132TB of compressed trace information totaling 74 billion traces. Our p50 to retrieve a trace is ~two.two seconds.
Correlations between metrics, logs, and traces
With Tempo, the vision for much more correlations between metrics, logs, and traces is becoming a fact.
Linking from logs to traces
Take into consideration a line such as:
route=/api/v1/end users standing=500 latency=25ms traceid=598083459f85afab userid=4928
All of these fields now present a searchable index for your trace IDs in Tempo. By indexing our traces with our logs we enable individual groups to customise their indexes into their traces. Every single team can log on the similar line as trace ID any field that is meaningful to them and it immediately produces a searchable field for traces as effectively.
As of Loki two., if any log has an identifier for a trace, you can simply click on it and soar immediately to that trace in Tempo.
 Grafana Labs
Grafana LabsLinking from metrics to traces
Making use of exemplars, traces can now be discovered immediately from metrics.
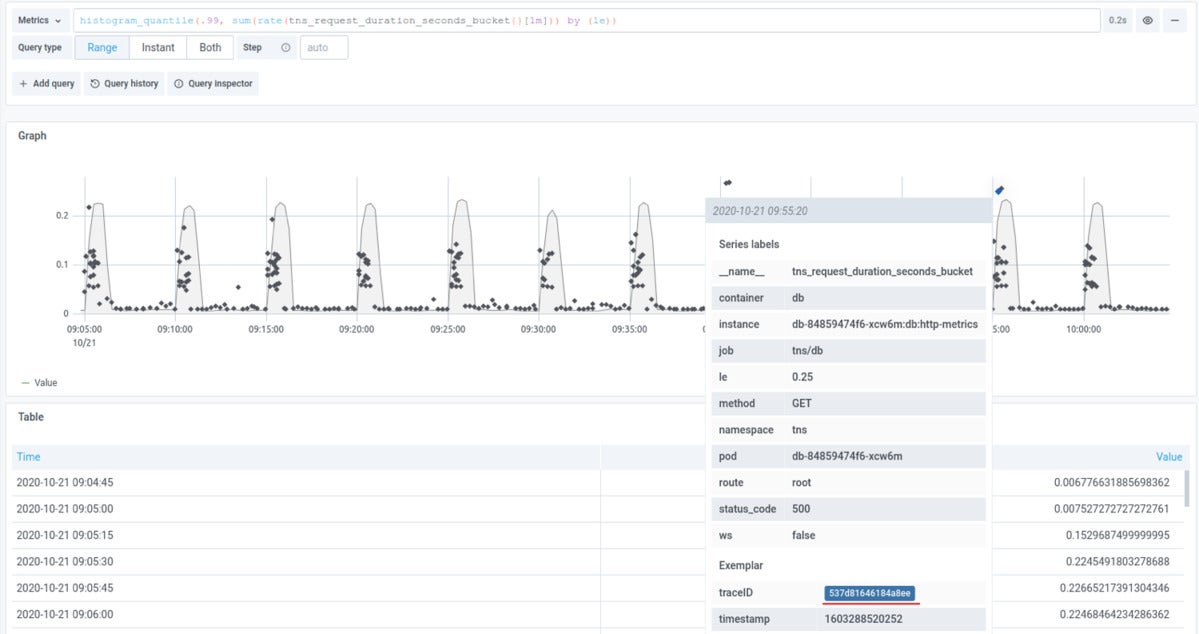 Grafana Labs
Grafana LabsLogs enable you to obtain the exact trace you’re seeking for centered on logged fields, although exemplars let you obtain a trace that exemplifies a pattern. You can have inbound links to traces centered on your metrics query immediately embedded in your Grafana graph. Phone up p99s, 500 mistake codes, or particular endpoints employing a Prometheus query, and all of your traces now come to be suitable illustrations of the pattern you’re looking at.
Linking from traces to logs
So exemplars and logs can be utilized for discovery, and Tempo can be utilized for storing almost everything with out worrying about the monthly bill. To website link from a trace back again into logs, the Grafana Agent makes it possible for you to adorn your traces, logs, and metrics with consistent metadata, which then produces correlations that were not previously feasible. Just after leaping from an exemplar to a trace, you can now go immediately to the logs of the having difficulties company. The trace instantly identifies what aspect of your ask for route brought about the mistake, and the logs enable you identify why.
 Grafana Labs
Grafana LabsUnderstand much more about Grafana Tempo
Sign up for us in the Grafana Slack #tempo channel or the tempo-end users Google group, and watch our GrafanaCONline session, “Open supply distributed tracing with Grafana Tempo,” for a deeper dive into Tempo. Tempo distributed tracing is also now accessible as portion of the free of charge and paid tiers of our thoroughly managed, composable observability platform, Grafana Cloud 50 GB of traces are incorporated in the free of charge tier.
Joe Elliott is principal engineer at Grafana Labs.
—
New Tech Discussion board supplies a location to explore and explore rising company technology in unparalleled depth and breadth. The collection is subjective, centered on our pick of the technologies we believe that to be important and of best curiosity to InfoWorld audience. InfoWorld does not take marketing collateral for publication and reserves the correct to edit all contributed content. Ship all inquiries to [email protected].
Copyright © 2021 IDG Communications, Inc.






